EOS Network Congestion by DDoS Analysis
Article credited to Dexaran and provided by EOS GO

Sir, you are being DDOSed ...
This article describes EOS congestion from attacker's point of view and provides real examples of what can be done, how much it will cost, what the consequences will be and how exactly it will hurt the UX.
Personally, it seems to me that the congestion of the network takes too long to recover and resume its normal state. To increase the cost of a similar attack, the state of the network and the congestion should resolve faster.
What is EOS network congestion?
This is what we need to know about the network congestion:
Within EOS, blocks are created 500 milliseconds apart. To help ensure that Block Producers have enough time to propagate blocks around the world, there is a per-block processing time limit of 200 milliseconds within which a Producer has to validate the block before broadcasting it to the network. This leaves 300 milliseconds for propagation across the network.
Another constraint is that within the cap of 200 milliseconds, there is also a percentage threshold at which rate limiting begins. Before this limit is reached, all users can freely transact on the network as it is not in “congestion mode.” Once this limit is passed, users are throttled back to their pro-rata share of the total CPU-per-staked-EOS allotment.
I recommend reading this article for more detailed info.
Before we start: preliminary research and congestion session design
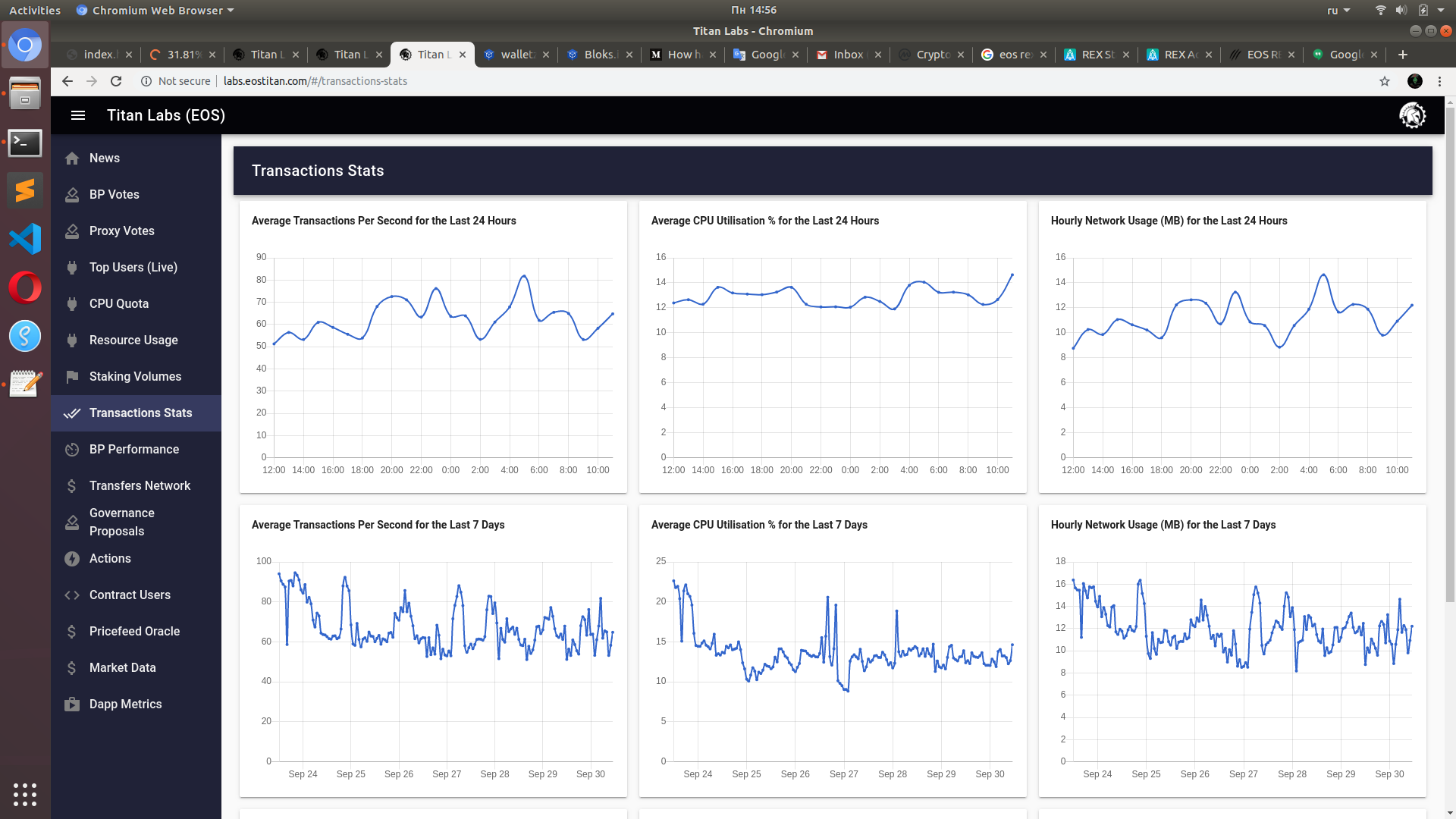
We can monitor live EOS network stats at http://labs.eostitan.com/#/cpu-quota/ (thanks to EOS Titan Labs for the handy tool).
I did a bit of research before I started.

As you can see in the screenshot above, the CPU usage spikes on the EOS network at the beginning of each hour. I figured out that it is EOSBetDice DApp that is processing something really actively at that times.
So, I decided to rely on a help of EOSBetDice during my artificial congestion session. It's easier to initiate congestion by consuming large amounts of CPU. The more CPU you consume in a row, the "deeper" a congestion mode will be and the longer it will take for the network to recover to its normal mode. Once the "congestion" starts the amount of CPU of each user will start decreasing until every congesting party runs out of CPU and stops processing CPU-consuming actions.
Normally DApps have tremendous amount of CPU staked, so it is hard to make them stop. However, we can target DApp users instead.
-
The more CPU staked an account has, the higher the chance that this account will withstand the congestion (i.e. it will not lose the ability to transact during the spike of CPU overdraw)
-
The less CPU is already consumed by an account, the higher the chance that this account will withstand the congestion
-
EOS congestion mechanic has a degree of lagging so it will keep lowering CPU more and more even when you run out of CPU if you have spammed the network for some continuous time. This means that the most effective way to push EOS into a deep congestion is to stake as much CPU as you can, then fully replenish your CPU, then stress the netowork with resource-consuming transactions and stop when you run out of CPU. Then you should wait until your CPU will FULLY REPLENISH (i.e. the network will be back to its normal mode) and repeat.
Lets take a look at the betdicegroup contract. It has 922K EOS of CPU. There is no way that our congestion session will affect this contract and we can rely on an assumption that it will be operating normally even at the pike phase of our congestion.
So, the plan is as follows:
-
Design and deploy a CPU-consuming contract
-
Wait for the beginning of an hour (the moment when
betdicegroupwill start processing its transactions) -
Initiate the congestion session so that the
betdicegroupcontract will engage right after we pushed the EOS network into the hardest congestion we could achieve at our own
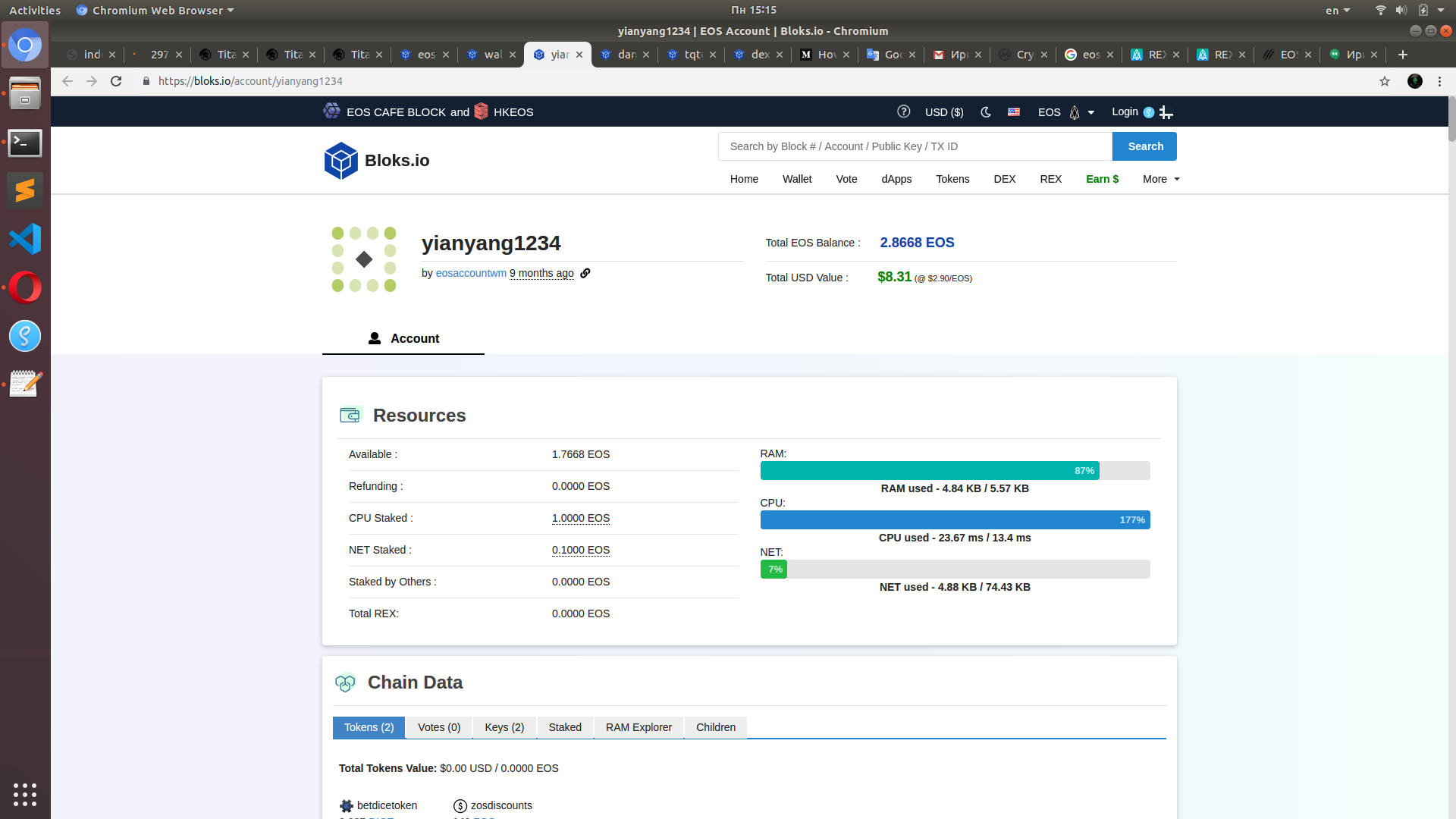
To evaluate the consequences let's find some guys to watch at during the congestion session. I've navigated to eosknightsio contract and picked three random guys who had used some of their CPU already.
Meet our new friends: yianyang1234, dangtehou123 and tqtq11111111.
Also, there are REX and Chintai resource exchanges in EOS. For some reason the prices at Chintai are higher. Chintai has an automated resourcing feature so it is also worth watching.
The final question is how much CPU we need to push the network into congestion. It turns out that 5,000 - 10,000 EOS is enough to harm the ecosystem. I'm using 7,156 EOS staked for CPU and 7 EOS staked for NET. It should be noted that you can buy 4000 EOS for 1 month in REX and it will cost you 1 EOS. So, the cost of my congestion scheme is 2 EOS per month.
Even more, my account had 3 min of CPU already spent when I started this session. Congesting with fully replenished CPU is much more efficient.
The final look at the ecosystem before we start
I have this congester contract.
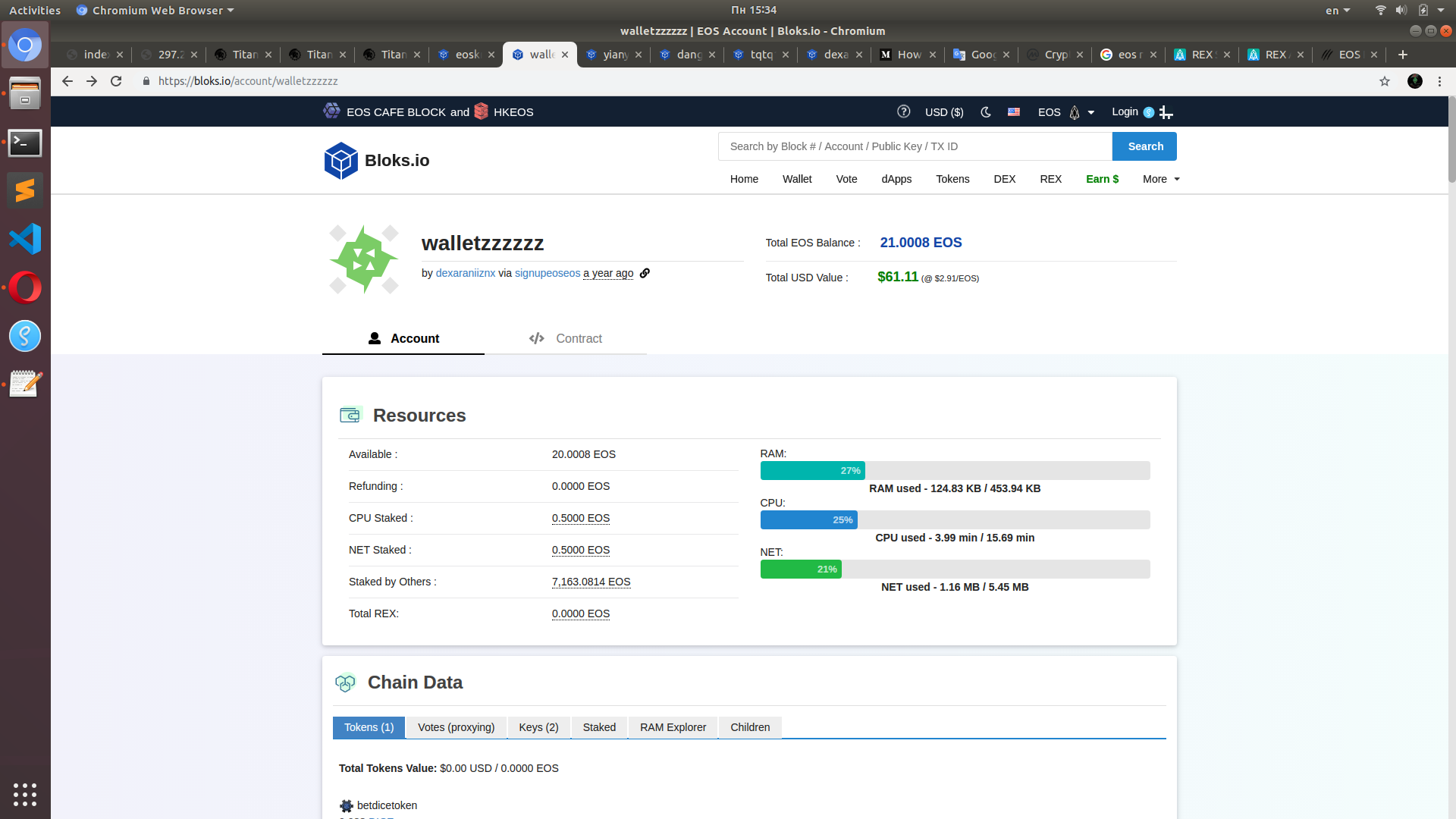
It was deployed here: walletzzzzzz
Normally it has 16.28 min of CPU. I had 3,87 min already spent, but it is not so important for us now.

Here is some network info:

Here is the state of EOSKnights contract. It has 0% of CPU used which means that it will not suffer from our congesting activities:

Here is our friend yinyang1234 playing EOSKnights 2 minutes before the congestion session:

And here is Chintai 7D market:

I assume that the displayed Chintai price surge was caused by my recent contract tests and experiments.
Here are users and their stats:



The moment we start it: 15:00
I've executed three calls of set function of the contract. The contract spawns a lot of deferred transactions (870 to be honest) with a delay of 1 second each. Each of the transactions should have consumed 25 to 27 ms of CPU. Deferred transactions filled the RAM of the contract.
My already used CPU starts rising while the max amount of CPU starts decreasing. This means that the network is pushed into a congestion mode:

15:01 - contract is working
The contract monopolized CPU utilization for a minute.

As you can see at the screenshot above the contract utilized 44% of CPU.
15:02 - contract runs out of CPU, the first phase of congestion mode ended
Here are the network stats:

Here is my contract that ran out of available CPU:

It should be noted that the contract could perform even more congestion if it would be fully replenished. The contract stops when it surpassed the 3.99 min of already spent CPU. There were 3.87 min CPU spent when I started and the contract stopped at 3.99. I spent 0,12 min CPU out of 16.29 total CPU of my account.
It would require ~ 3 min CPU for my contract to repeat this congestion session each hour at EOS mainnet for 24 hours/day. This means that I could repeat this congestion sessions over and over each hour. My total CPU limit (16 min) will not run out because I'm not consuming 100% of my CPU, I only need a congestion spike that is relatively cheap for me.
15:02 - let's take a look at our friends



So, this guys are out of CPU. They can't transact. They can't rent resources at this moment. They are frozen completely.
15:03 - eosbetdicegroup is approaching the scene
EosBetDice starts its own congestion as expected. The congestion mode continues and CPU shrinked even more.


15:04 - just some stats

15:05 - congestion mode reached its deepest point

As you can see at the screenshot above my account had 28.32 seconds of CPU instead of 16.29 minutes. CPU availability shrinked by 35x. Resource availability is shrinking proportionally for each member of the network so we can conclude that everyone who had more than 3% of CPU already used were frozen. No matter how much EOS you staked for CPU - if you have used more than 3% then you would be frozen.
CPU starts replenishing slowly and congestion mode starts to resolve. The problem here is the fact that it is replenishing TOO SLOW.
15:08 - 3 minutes after the critical point of congestion
Please take a look at our accounts:




A bit of network stats at 15:08

It should be noted that no one is congesting the network at this point of time. We stopped already. We stopped 3 minutes ago. But most of the accounts are frozen.

Watch the gray area named "others" at the screenshot above. Normally it represents the share of CPU consumed by small Dapps and mere users. Now it became smaller which means that a lot of users stopped transacting. Largescale DApps like EosKnights and EosBetDice were fine. Users were those who got problems.
15:14 - the consequences
Chintai and automated resourcing in action:

3 days ago the APR of lending your EOS were ~6-7%. Now the APR at Chintai is 297%.
We are still frozen. No one is congesting the network for 10 minutes already but most of accounts are frozen yet. We were effectively stressing the network for 5 minutes (15:00-15:02 my contract/ 15:02 - 15:05 eosbetdice) and we got 10 additional minutes for free.



It seems that this congestion resolving mechanic is lowering the cost of a DDOS attack. Imagine that I'm a bad guy and I'm willing to harm the network. I should cause a CPU price spike and then I don't even need to spend resources to maintain the network in congestion mode. The network will be recovering for so long that I can save my resources for the next wave of congestion.
If the network will be recovering from congestion faster then I would need to spend more of my own CPU on pushing it into congestion again and again which will rise the cost of the attack for me.
15:17 - our first friend recovered from congestion
Congratulations tqtq11111111

15:21 - the network recovers
The network has almost recovered, but the price of CPU is still 3x higher than in a normal mode. 16 minutes after the last "congesting" activity at the network.




I doubt that the guys at the screenshots above are still sitting with their EOS wallets waiting for congestion to resolve. Its likely that they got disappointed by the 21-min-length lock up and they got to do something else.
15:27 - others are taking their share back

15:34 - the network is back to normal mode
My total CPU time is almost 16 min again. It took 30 minutes for the network to recover since the last "malicious" action. Users are given a window of 25 minutes until the next congestion session.
Conclusion
7000 EOS is enough to push EOS network into a congestion mode for a decent amount of time. You can rent it at REX for 2 EOS/month.
According to randomly selected players of EosKnight, resource rental price spike and volume growth, live network charts and rough calculations the described congestion session had recognizable impact.
Slow rate of network congestion recovering is lowering the cost of a DDOS attack.
The described congestion session will only cause problems for (1) users who spent a certain share of their CPU bandwidth, (2) users with very low CPU bandwidth staked.
The described congestion session has no impact on (1) DApps that have a lot of CPU available, (2) users who do not engage in any activity and have their CPU fully available (assuming that these users have enough CPU to make a single tx).
Users can resist this congestion with a help of resource exchanges or significant amount of CPU bandwidth staked, however it may seem unreasonable for a mere user to have more CPU bandwidth than he is normally consuming on his own.
P.S. I'm not DDOSing. I'm emulating the mass adoption of the platform.
Well, some could possible call me a "hacker" or an "attacker".
I'd like to argue that I did not attacked or harmed something. I'm doing exactly the opposite: I'm protecting my investments and yours. I'd like to (1) facilitate the healthy growth of the platform, (2) educate the users about the core features and possible issues, (3) incentivise voters to choose Block Producers with high performance, (4) research possible improvements.
Feel free to tip any of my accounts so that we don't need to stress Chintai for 297% APR anymore.
Disclaimer: The views expressed by the author above do not necessarily represent the views of EOS GO. EOS GO is a community where EOS GO Blog being a platform for authors to express their diverse ideas and perspectives. Any referral links present were placed directly by the author, from which EOS Go does not derive any benefits. To learn more about EOS GO and EOS, please join us on our social medias.
EOS GO is funded by EOS ASIA and powered by YOU. Join the community and begin contributing to the movement by adding eos go to your name and joining the EOS GO telegram group.